

I think that every UX designer who is interested in this topic will sooner or later come across this page.
There is a graph on this page that shows how many respondents find the number of usability errors. There is also formula on how the authors came to these numbers.
N (1- (1-L) n)
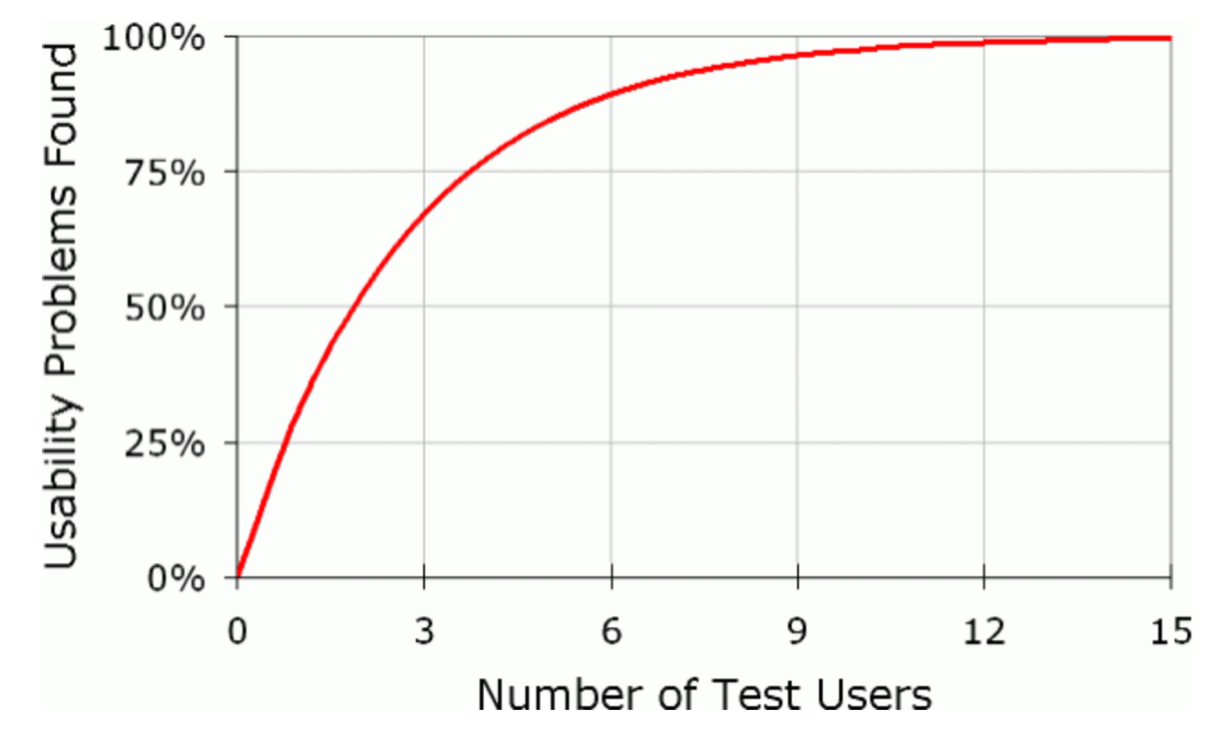
Source: https://www.nngroup.com/articles/why-you-only-need-to-test-with-5-users/
If we take a closer look at the formula, we find that it considers N, the number of errors found, and L, the proportion of problems one respondent finds. L is 31%, which is observed from the authors of large projects.
When we do not give great importance to the calculation, we expect five respondents to detect 85% of the application's usability errors.
But this is not the end of the article…
The problem is the L. This can be explained as follows (I will quote another article here). Five respondents will find 85% usability errors if 1 in 3 users has the problem. Then all this can work.
Here it could be said that if 1 out of 3 users has a usability problem, it would probably be enough to test with three respondents. But this is not how the real world works. Try tossing a coin with thinking that you want the head to fall. You may throw three times before it works. And you have a 50% chance that the head will fall. If you are interested in more about this issue, I recommend reading this article.
The magic number 5 actually describes the probability that thanks to 5 respondents, you will detect 85% of errors in case an error occurs to 1 in 3 users. It will become more complicated if 1 in 10 users have a problem. In that case, you would need 18 respondents to find 85% of the errors. It is advisable to keep this in mind when recruiting for tests. Suppose a technologically proficient target group is invited. In that case, it may happen that the parts that are tested will be understandable for them, and therefore the problem with usability will have only 1 out of 10 or 1 out of 20.
Thanks to this, the test with five respondents may not reveal these problems. Once the product is released and the target audience isn't as proficient, one in three may suddenly have a usability problem. As a result, this may mean that people will have a problem with the product's usability, which may not be revealed thanks to the choice of a technologically experienced target group for testing. It also happened to us that we tested the prototype three times, together with 15 respondents, and we perceived it as very well tested. But then, in further tests, new bugs on the already tested functionality began to appear. Differences between the groups caused this, and suddenly we had an entirely new perspective on the issue.
Conclusion
From our experience, it makes sense to test with five respondents. Both economically and organizationally. But it does not mean that most problems can always be found.
Therefore, it is advisable to constantly repeat the test and choose respondents who will most likely have usability problems (e. g., people less experienced in technology). This will increase the likelihood that you will find more errors.
You can also increase the effectiveness of user tests by increasing the number of tasks that respondents do, thus increasing the likelihood of finding additional errors.
Finally, it is helpful to identify parts of the prototype, application, or website in which may be more difficult to detect errors. It is advisable to subject these sections to more user tests so that you can go through the functionality with 10 or 20 respondents and thus increase the probability of detecting an error.





